What is Data Science Product Development?

Data science product development is the next stage in product management where data science, AI, and machine learning models help enhance product development.

Credits: Medium
Data science products help business optimize their processes, making them more efficient. They also generate new ways of bringing value to businesses.
Above all, data science product development relies on constant innovation. The teams that manage data science products require a deep understanding of the product roadmap, along with data science concepts like artificial intelligence and deep learning.
What Are Data Science Products?
Data science products are any tool, application, or software that utilizes data to help companies improve decision-making and processes.
Data products have a friendly user interface at the front end. However, at the backend, they use data science to provide descriptive data modeling, predictive analytics, data mining, and risk management.
Data scientists and data analysts are not the only professionals who work on data science products. Anyone with sufficient knowledge makes use of them because the UI is similar to traditional software.
As companies adopt a data-driven culture, they use insights from these data products to reach business objectives and make informed decisions at every turn.
At each point in the product lifecycle, companies use the data to make better decisions. The data comes from customers, market analytics, surveys, website visitor behavior, and other data assets. Data-driven analyses of such data assets discover new trends, efficiencies, and gaps that drive economic value.
Data Science Product Examples
One of the most common data science product examples is Google Analytics. Similar to website analytics tools, these tools use real-time data along with historical trends to provide you with up-to-date data on your website and its current position.
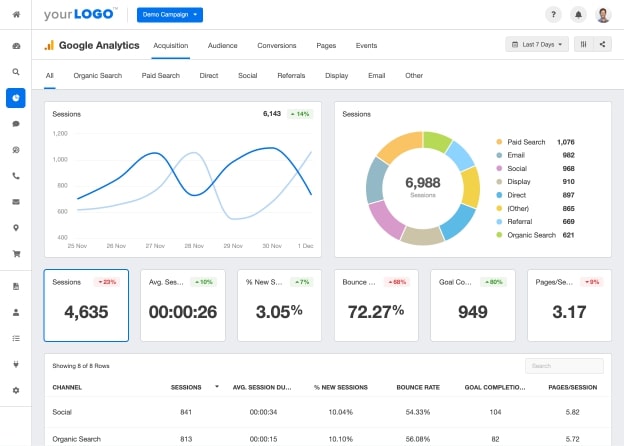
Credits: Agency Analytics
Other examples include finance terminals like the Bloomberg Terminal and customer predictive analytics tools like the Einstein AI by Salesforce.
Many companies opt for in-house development of a product model or data products to foster privacy and data integrity.
The products serve a specific need and have a product owner that defines the business cases for it. However, the more customizable and flexible it is, the more scalable it is. This helps determine how valuable the data product is within the organization.
Incorporating data products in your product strategy and business helps free valuable resources. Your product teams, data science teams, and other teams that manage the data are going to spend less time cleaning, preparing, and analyzing data.
Data engineering, data analytics, and data science projects have a lot of manual and tedious tasks. Data products help automate such tasks or provide better insights on how to improve certain processes.
Regardless, all the data products need to share certain commonalities. For starters, they must be easy to use. They must also be a scalable solution that’s adaptable and customizable. That’s because your data scientist or data science product manager isn’t the only person who needs to access the product.
You must therefore make it accessible to business stakeholders, other product managers, and the rest of the product team.
Need for Data Science Product Development Strategies
As organizations realize the economic value of their data assets, they invest more in data products. They assess the value of the data itself, along with the revenue that comes from data-based business models.

As more use cases for such data science products come up, these models come in handy for more tasks. This leads companies to move towards embedded analytics integrations and various data monetization opportunities.
The revenue that comes from such business models is a key indicator of digital success today. That’s because data science responsibilities continue to expand into new areas. That includes the economic success of the data business and all of its supporting technology.
While explaining the business value of data science product development strategies, data science product managers use the slogan, “Data is the new oil.”
However, that leads to a few questions that each organization has to answer:
- How do you extract this oil/data?
- Where do you store it?
- How do you refine it?
- How must you transport it?
- How do you incorporate it into your existing business model?
Answering these questions lays down the foundation for your data science product development processes.
History of Data Science Product Development
The history of data science products and how they have become commonplace starts with the realization of the importance of data. We must summarize the timeline into six key stages.
- 1962 – John Tukey’s “The Future of Data Analysis” came into play, establishing a relationship between data analysis and statistics. Moving to 1974, Peter Naur’s “Concise Survey of Computer Methods” came into play, coining the term, ‘data science.’
- 1977 – Further research into the importance of data helped establish the International Association of Statistical Computing (IASC). Fast forward to 1989, we see the establishment of the Knowledge Discovery in Databases (KDD) – the first workshop on Data Discovery.
- 1994 – The rise of software engineering, product-based data, and the need for analyzing data paved a way for data science. As companies went on to stockpile massive amounts of data, they didn’t have much idea of what to do yet. In 1996, the term Data Science showed up at the International Federation of Classification Societies (IFCS).
- 2000s – At this point, data science came into play as academic journals began to recognize it. Data science and big data started to work together with the developing technology.
- 2013 – DJ Patil and Jeff Hammerbacher coin the term Data Scientist. In 2013, an IBM report found that 90% of the world’s data came in the last two years. At this point, companies had begun to treat data as a commodity. Specialists started to convert large clusters of data into usable information.
- Present Day – Major tech giants shifted towards data science for developing their products. Several startups in the San Francisco Bay Area and Silicon Valley sprout up utilizing deep learning, artificial intelligence, and machine learning to capitalize on data science.
That brings us to modern-day data science product development.
Data Science Product Development Roles
Each data science team usually has one data science product manager who overlooks all product-related matters. A data product manager is someone who understands data science and product management.
It’s their job to determine whether the right data is reaching the data science and analysis team. Their focus is then on how the results of the data analysis apply to the product they’re working on.
It’s hard to find a product person who understands data science. That’s why most companies get their data scientists re-trained to better understand product management.
Other than the product manager role, some common roles that support data science product development include:
- Product Owner – Manages the product backlog and development.
- Data Scientist – Convert raw data into usable insights and information.
- Researchers – Collect data and relay it to data scientists.
- Data Architect – Creates blueprints for data management.
- Business Analysts – Help connect the dots to use the insights into current business processes.
Other common roles include statisticians, data engineers, data administrators, data analysts, product marketing managers, and the Chief Product Officer (CPO).
What is Agile Data Science Product Development?
First, let’s take a look at the agile data science principles to establish a foundation:
- Iterate everything from tables to charts, predictions, and reports.
- Ship out intermediate output because even failed experiments have valuable outputs.
- Give precedence to prototyping experiments over task implementation.
- In product management, integrate the tyrannical opinion of data.
- The critical path discovery leads to great products.
- Going both up and down in the data-value pyramid is the way to go.
- Note the process and not only the end state.
Keeping these principles in mind, summarize the agile data science product development process in eight steps.
- Define the business need, along with the project objective. This is the responsibility of the product owner who establishes key product features and has knowledge of the subject.
- Build the backlog by focusing on user requirements and customer needs. Ill-defined requirements lead to issues in later stages.
- Prioritize each backlog task by choosing tasks that bring more value with less effort.
- Do a sprint in two-week cycles where you work on high-priority tasks.
- Organize daily standups to hold team members accountable.
- Review sprint outputs for each project team.
- Prepare the next sprint by identifying key tasks again.
- Roll out the final product when all the stakeholders agree that the product requires no further improvements.
Regardless of your team’s expertise, ideas, and knowledge, all data science projects have a law of diminishing improvement. Each additional improvement requires an exponential amount of effort.
Data Science Product Development in the Future
The integration of data science products into businesses is only going to increase in the future. Moving forward, any company that doesn’t utilize data science is bound to fall behind the curve.
Meanwhile, as machine learning algorithms and AIs become more sophisticated, our data science products are also going to improve.













